reStructuredText test page
The following page presents reStructuredText examples and how they look on the site. Compare the source of this page with how it looks on the site (after the build) to learn how everything is rendered. Not everything may look pretty - reStructuredText is an output-agnostic format and this website build process does not implement every possible reStructuredText feature. While the HTML may be well generated, majority of reStructuredText features rely on CSS.
This page should not be treated as an reStructuredText learning material. At most as a quick refresher. For learning reStructuredText, read first:
User documentation:
reStructuredText Cheat Sheet (text only)
Reference documentation:
Most of the content on this page comes from these materials (primarily demo and directives). I have pasted examples only of features that have support on this site.
Custom directives (implemented as additions specifically for this site) can be found at the bottom of this article.
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
Unlike Markdown, reStructuredText does not specify exact characters for any heading. It will create smaller headings as long as each further-nested heading uses a different character. The underline/overline character sequence must be at least as long as the heading text.
It is recommended to stick to the order presented above for consistency (# - 2, = - 3, - - 4, ~ - 5, _ - 6). There is no <h1> heading example because for every page, the generator will automatically prepend such heading with the page title (specified in metadata at the top of the source file).
Paragraphs
Paragraphs are separated by blank lines.
Don't line-wrap long text manually by inserting line breaks. Enable line wrap in editor and leave wrapping up to the final content reader (e.g. web browser). Long text will be rendered in multiple lines, but from the source file point of view it should be on the same line.
Inline markup
By definition, in all inline markups line breaks are not allowed. Inline markup can not be nested.
italic text - surround text by *. Use to indicate a term/keyword.
bold text - surround text by **. Use to indicate something important.
literal text - surround text by ``. Use to indicate any form of code.
Interpreted text
Interpreted text (text surrounded by single `) is not intended for literal text but for domain- or application-specific meaning. So far there is only 1 use of interpretext text - custom code highlight (with explicit naming of the cch plugin). Search (unwanted) uses of interpreted text by grep -rn "[^\`:]\`[A-Za-z0-9_ ]\+\`[^_\`]" --include="*.rst" website/pages/ (the only results should be on the this test page).
Escaping
If you find that you want to use one of the "special" characters in text, it will generally be OK -- reStructuredText is pretty smart. For example, this lone asterisk * is handled just fine, as is the asterisk in this equation: 5*6=30. If you actually want text surrounded by asterisks to not be italicised, then you need to indicate that the asterisk is not special. You do this by placing a backslash just before it, like so "*". Inline markup by itself (surrounded by whitespace) or in the middle of a word won't be recognized - it has to be escaped like in the following sentence:
Possible in reStructuredText, though not encouraged.
Inline markup - HTML
Do not use HTML tags inside reStructuredText pages. reStructuredText exists with its features to avoid manually writing HTML (or other output-specific) markup. HTML in reStructuredText sources will be escaped and render <u>unformatted</u>.
Explicit Markup
Explicit markup blocks are used for constructs which float (footnotes), have no direct paper-document representation (hyperlink targets, comments), or require specialized processing (directives). They all begin with two periods and whitespace, the "explicit markup start".
The numbering of auto-numbered footnotes is determined by the order of the footnotes, not of the references. For auto-numbered footnote references without autonumber labels ([#]_), the references and footnotes must be in the same relative order. Similarly for auto-symbol footnotes ([*]_).
References
Example 1
Footnote references, like [5]. Note that footnotes may get rearranged, e.g., to the bottom of the "page".
Example 2
Autonumbered footnotes are possible, like using [1] and [2].
They may be assigned 'autonumber labels' - for instance, [4] and [3].
Example 3
Auto-symbol footnotes are also possible, like this: [*] and [†].
Citations
Citation references, like [CIT2002]. Note that citations may get rearranged, e.g., to the bottom of the "page".
A citation (as often used in journals).
Citation labels contain alphanumerics, underlines, hyphens and fullstops. Case is not significant.
Given a citation like [this], one can also refer to it like this.
here.
Hyperlink Targets
External Hyperlink Targets
External hyperlinks, like Python.
Embedded URIs
External hyperlinks, like Python.
Links inside the website
Nikola has a built-in feature do to it, like this: reST test.
Internal Hyperlink Targets
Internal crossreferences, like example.
This is an example crossreference target.
Indirect Hyperlink Targets
The second hyperlink target (the line beginning with "__") is both an indirect hyperlink target (indirectly pointing at the Python website via the "Python" reference) and an anonymous hyperlink target. In the text, a double-underscore suffix is used to indicate an anonymous hyperlink reference. In an anonymous hyperlink target, the reference text is not repeated. This is useful for references with long text or throw-away references, but the target should be kept close to the reference to prevent them going out of sync.
Implicit Hyperlink Targets
Section titles, footnotes, and citations automatically generate hyperlink targets (the title text or footnote/citation label is used as the hyperlink name).
Implict references, like Heading 2 are automatically linked.
Substitution References and Definitions
Substitutions are like inline directives, allowing graphics and arbitrary constructs within text.
The 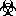 symbol must be used on containers used to dispose of medical waste. And here is a fancy jumping ball:
symbol must be used on containers used to dispose of medical waste. And here is a fancy jumping ball:  .
.
Blockquotes
Generates <blockquote> elements. Has CSS support implemented. Block quotes are just indented paragraphs and they may nest.
Destructors for virtual base classes are executed in the reverse order of their appearance in a depth-first left-to-right traversal of the directed acyclic graph of base classes - Bjarne Stroustrup.
Literal Blocks
A paragraph containing only two colons indicates that the following indented or quoted text is a literal block.
Whitespace, newlines, blank lines, and all kinds of markup (like *this* or \this) is preserved by literal blocks. The paragraph containing only '::' will be omitted from the result.
The :: may be tacked onto the very
end of any paragraph. The :: will be
omitted if it is preceded by whitespace.
The :: will be converted to a single
colon if preceded by text, like this:
It's very convenient to use this form.
Literal blocks end when text returns to the preceding paragraph's indentation. This means that something like this is possible:
We start here and continue here and end here.
Per-line quoting can also be used on unindented literal blocks:
> Useful for quotes from email and > for Haskell literate programming.
Parsed Literal Blocks
Unlike an ordinary literal block, the "parsed-literal" directive constructs a literal block where the text is parsed for inline markup. It is equivalent to a line block with different rendering: typically in a typewriter/monospaced typeface, like an ordinary literal block. Parsed literal blocks are useful for adding hyperlinks to code examples.
However, care must be taken with the text, because inline markup is recognized and there is no protection from parsing. Backslash-escapes may be necessary to prevent unintended parsing. And because the markup characters are removed by the parser, care must also be taken with vertical alignment. Parsed "ASCII art" is tricky, and extra whitespace may be necessary.
This can be useful for presenting heavily-formatted text that is not strictly code. A good example are grammar specifications:
function-specifier:
virtual
explicit-specifier
explicit-specifier:
explicit ( constant-expression )
explicit
placeholder-type-specifier:
type-constraint(optional) auto
type-constraint(optional) decltype ( auto )
Line Blocks
This feature has no CSS support for it right now. Additionally, HTML discards repeated whitespace much makes this feature troublesome for HTML output.
Doctest Blocks
Doctest blocks are interactive
Python sessions. They begin with
">>>" and end with a blank line.
>>> print "This is a doctest block." This is a doctest block.
This feature has no direct support in CSS. Use code directive instead.
Lists
Implemented lists
Note that a blank line is required before the first item and after the last, but is optional between items.
Bullet lists
This is item 1
This is item 2
-
Bullets are "-", "*" or "+". Continuing text must be aligned after the bullet and whitespace.
This is a sublist. The bullet lines up with the left edge of the text blocks above. A sublist is a new list so requires a blank line above and below.
Enumerated lists
This is the first item
This is the second item
Enumerators are arabic numbers, single letters, or roman numerals
List items should be sequentially numbered, but need not start at 1 (although not all formatters will honour the first index)
This item is auto-enumerated
Unsupported lists
Not recommended to use, not implemented and likely will not be needed:
definition list
field list
option list
Definition lists
- what
-
Definition lists associate a term with a definition.
- how
-
The term is a one-line phrase, and the definition is one or more paragraphs or body elements, indented relative to the term. Blank lines are not allowed between term and definition.
Field Lists
- Authors:
-
Tony J. (Tibs) Ibbs, David Goodger (and sundry other good-natured folks)
- Version:
-
1.0 of 2001/08/08
- Dedication:
-
To my father.
Option Lists
There must be at least two spaces between the option and the description.
- -a
-
command-line option "a"
- -b file
-
options can have arguments and long descriptions
- --long
-
options can be long also
- --input=file
-
long options can also have arguments
- /V
-
DOS/VMS-style options too
Tables
There are two syntaxes for tables in reStructuredText. Grid tables are complete but cumbersome to create. Simple tables are easy to create but limited (no row spans, etc.).
Grid table
Header 1 |
Header 2 |
Header 3 |
|---|---|---|
body row 1 |
column 2 |
column 3 |
body row 2 |
Cells may span columns. |
|
body row 3 |
Cells may span rows. |
|
body row 4 |
||
Simple table
Inputs |
Output |
|
|---|---|---|
A |
B |
A or B |
False |
False |
False |
True |
False |
True |
False |
True |
True |
True |
True |
True |
CSV Table
The "csv-table" directive is used to create a table from CSV (comma-separated values) data. CSV is a common data format generated by spreadsheet applications and commercial databases. The data may be internal (an integral part of the document) or external (a separate file).
Example:
Treat |
Quantity |
Description |
|---|---|---|
Albatross |
2.99 |
On a stick! |
Crunchy Frog |
1.49 |
If we took the bones out, it wouldn't be crunchy, now would it? |
Gannet Ripple |
1.99 |
On a stick! |
Block markup and inline markup within cells is supported. Line ends are recognized within cells.
Working limitations:
There is no support for checking that the number of columns in each row is the same. However, this directive supports CSV generators that do not insert "empty" entries at the end of short rows, by automatically adding empty entries.
Whitespace delimiters are supported only for external CSV files.
With Python 2, the valuess for the
delimiter,quote, andescapeoptions must be ASCII characters. (The csv module does not support Unicode and all non-ASCII characters are encoded as multi-byte utf-8 string). This limitation does not exist under Python 3.
The following options are recognized:
-
widthsinteger [, integer...] or "auto" -
A comma- or space-separated list of relative column widths. The default is equal-width columns (100%/#columns).
The special value "auto" may be used by writers to decide whether to delegate the determination of column widths to the backend (LaTeX, the HTML browser, ...).
-
widthlength or percentage of the current line width -
Forces the width of the table to the specified length or percentage of the line width. If omitted, the renderer determines the width of the table based on its contents.
-
header-rowsinteger -
The number of rows of CSV data to use in the table header. Defaults to 0.
-
stub-columnsinteger -
The number of table columns to use as stubs (row titles, on the left). Defaults to 0.
-
headerCSV data -
Supplemental data for the table header, added independently of and before any
header-rowsfrom the main CSV data. Must use the same CSV format as the main CSV data. -
filestring (newlines removed) -
The local filesystem path to a CSV data file.
-
urlstring (whitespace removed) -
An Internet URL reference to a CSV data file.
-
encodingname of text encoding -
The text encoding of the external CSV data (file or URL). Defaults to the document's encoding (if specified).
-
delimchar | "tab" | "space" -
A one-character string used to separate fields. Defaults to
,(comma). May be specified as a Unicode code point; see the unicode directive for syntax details. -
quotechar -
A one-character string used to quote elements containing the delimiter or which start with the quote character. Defaults to
"(quote). May be specified as a Unicode code point; see the unicode directive for syntax details. -
keepspaceflag -
Treat whitespace immediately following the delimiter as significant. The default is to ignore such whitespace.
-
escapechar -
A one-character string used to escape the delimiter or quote characters. May be specified as a Unicode code point; see the unicode directive for syntax details. Used when the delimiter is used in an unquoted field, or when quote characters are used within a field. The default is to double-up the character, e.g. "He said, ""Hi!"""
-
align"left", "center", or "right" -
The horizontal alignment of the table. (New in Docutils 0.13)
and the common options :class: and :name:.
List Table
The "list-table" directive is used to create a table from data in a uniform two-level bullet list. "Uniform" means that each sublist (second-level list) must contain the same number of list items.
Treat |
Quantity |
Description |
|---|---|---|
Albatross |
2.99 |
On a stick! |
Crunchy Frog |
1.49 |
If we took the bones out, it wouldn't be crunchy, now would it? |
Gannet Ripple |
1.99 |
On a stick! |
The following options are recognized:
-
widthsinteger [integer...] or "auto" -
A comma- or space-separated list of relative column widths. The default is equal-width columns (100%/#columns).
The special value "auto" may be used by writers to decide whether to delegate the determination of column widths to the backend (LaTeX, the HTML browser, ...).
-
widthlength or percentage of the current line width -
Forces the width of the table to the specified length or percentage of the line width. If omitted, the renderer determines the width of the table based on its contents.
-
header-rowsinteger -
The number of rows of list data to use in the table header. Defaults to 0.
-
stub-columnsinteger -
The number of table columns to use as stubs (row titles, on the left). Defaults to 0.
-
align"left", "center", or "right" -
The horizontal alignment of the table. (New in Docutils 0.13)
and the common options :class: and :name:.
Transitions
Transitions are commonly seen in novels and short fiction, as a gap spanning one or more lines, marking text divisions or signaling changes in subject, time, point of view, or emphasis.
A transition marker is a horizontal line of 4 or more repeated punctuation characters.
A transition should not begin or end a section or document, nor should two transitions be immediately adjacent.
Directives
Directives are a general-purpose extension mechanism, a way of adding support for new constructs without adding new syntax. For a description of all standard directives, see reStructuredText Directives.
Image
Inline images can be defined with an "image" directive in a substitution definition.
The URI for the image source file is specified in the directive argument. As with hyperlink targets, the image URI may begin on the same line as the explicit markup start and target name, or it may begin in an indented text block immediately following, with no intervening blank lines. If there are multiple lines in the link block, they are stripped of leading and trailing whitespace and joined together.
Optionally, the image link block may contain a flat field list, the image options.
Most useful options: alt and target (clickable image).
The following options are recognized:
-
alttext -
Alternate text: a short description of the image, displayed by applications that cannot display images, or spoken by applications for visually impaired users.
-
heightlength -
The desired height of the image. Used to reserve space or scale the image vertically. When the "scale" option is also specified, they are combined. For example, a height of 200px and a scale of 50 is equivalent to a height of 100px with no scale.
-
widthlength or percentage of the current line width -
The width of the image. Used to reserve space or scale the image horizontally. As with "height" above, when the "scale" option is also specified, they are combined.
-
scaleinteger percentage (the "%" symbol is optional) -
The uniform scaling factor of the image. The default is "100%", i.e. no scaling.
If no "height" or "width" options are specified, the Python Imaging Library (PIL) may be used to determine them, if it is installed and the image file is available.
-
align"top", "middle", "bottom", "left", "center", or "right" -
The alignment of the image, equivalent to the HTML
<img>tag's deprecated "align" attribute or the corresponding "vertical-align" and "text-align" CSS properties. The values "top", "middle", and "bottom" control an image's vertical alignment (relative to the text baseline); they are only useful for inline images (substitutions). The values "left", "center", and "right" control an image's horizontal alignment, allowing the image to float and have the text flow around it. The specific behavior depends upon the browser or rendering software used. -
targettext (URI or reference name) -
Makes the image into a hyperlink reference ("clickable"). The option argument may be a URI (relative or absolute), or a reference name with underscore suffix (e.g.
`a name`_).
and the common options :class: and :name:.
Figure
A "figure" consists of image data (including image options), an optional caption (a single paragraph), and an optional legend (arbitrary body elements). For page-based output media, figures might float to a different position if this helps the page layout.

This is the caption of the figure (a simple paragraph).
The legend consists of all elements after the caption. In this case, the legend consists of this paragraph and the following table:
Symbol |
Meaning |
|---|---|
 |
Campground |
 |
Lake |
 |
Mountain |
Unicode Character Codes
The "unicode" directive converts Unicode character codes (numerical values) to characters, and may be used in substitution definitions only.
The arguments, separated by spaces, can be:
-
character codes as
decimal numbers or
hexadecimal numbers, prefixed by
0x,x,\x,U+,u, or\uor as XML-style hexadecimal character entities, e.g.ᨫ
text, which is used as-is.
Text following " .. " is a comment and is ignored. The spaces between the arguments are ignored and thus do not appear in the output. Hexadecimal codes are case-insensitive.
For example:
Copyright © 2003, BogusMegaCorp™—all rights reserved.
Including an External Document Fragment
The "include" directive reads a text file. The directive argument is the path to the file to be included, relative to the document containing the directive. For example:
This first example will be parsed at the document level, and can thus contain any construct, including section headers. .. include:: inclusion.txt Back in the main document.
This can be useful for articles/tutorials which share same/similar set of information. Nikola also supports root-relative include paths, which are preferred in this project.
Code
The "code" directive constructs a literal block. Language and number-lines options are optional. Currently there is no Pygments-based highlighting. The indent needs to be the same for directive options and directive content.
The code directive is used on the website but only for non-highlighted code like shell output of sample programs. Use custom directives for highlighted code.
Non-highlighted code sample:
Unsupported
Do not use any other reStructuredText directive not mentioned on this page.
Custom directives
Details element
Creates spoiler-like element, using HTML <details> tag. Support through details_element plugin.
Optional option:
open(no arguments), causes the details element to be initially open (<details open>).Required option:
summary, text to always display (<summary>)
summary
content, which may be arbitrary reST content
list item A
list item B
list item C
Admonitions
There are some predefined admonitions but they do not allow to change the title text, which is a reason big enough to abandom them. Use only these custom admonitions:
Custom code highlight
Custom code highlight is implemented in rest_highlighter plugin. It offers 3 ways to generate highlighted code:
interpreted text (inline markup, not a directive)
mirror-based highlight (explicit semi-automatic colorization)
Clangd-based highlight (compiler-backed automatic colorization)
and one extra feature:
ANSI highlight (colorful terminal output)
For all directives, if paths begin with /, they are relative to the conf.py file, otherwise they are relative to the file containing the directive.
Inline interpreted highlight
The interpreted code must either:
Be defined in
data/inline_codes.cppand its highlight indata/inline_codes.color, matching line number. The code in interpreted text must be exact copy of a specific line. The code need not to be C++, the source file has justcppextension for better editor support. Example:std::string::npos.Have code and colorizarion written together in one interpreted text call, separated by
$$$token. Example:std::holds_alternative<typename T::value_type>(v).
More documentation about colorization can be found on the ACH readme.
Optional option: lang, defaults to CSS class used for C++.
Mirror highlight
Paths to both code and color spec are mandatory.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
#include <fmt> #include <iomanip> #include <iostream> #include <string> #include <type_traits> #include <variant> #include <vector> #ifdef SOME_MACRO #undef SOME_MACRO // macros are bad template <typename T> struct always_false : std::false_type {}; /** @brief alias for our variant */ using var_t = std::variant<int, long, double, std::string>; template <typename... Ts> struct overloaded : Ts... { using Ts::operator()...; }; template <typename... Ts> overloaded(Ts...) -> overloaded<Ts...>; template <typename T> concept Opaque = requires(T x) { {*x} -> typename T::inner; // the expression *x must be valid // AND the type T::inner must be valid // AND the result of *x must be convertible to T::inner }; template <Callable C, typename... Args> constexpr decltype(auto) execute(C&& func, Args&&... args) // constrained C++20 function template { return std::forward<C>(func)(std::forward<Args>(args)...); } template <typename Tuple, std::size_t... Is> constexpr bool are_sorted_impl(Tuple&& tuple, std::index_sequence<Is...>) { return !((std::get<Is + 1>(std::forward<Tuple>(tuple)) < std::get<Is>(std::forward<Tuple>(tuple))) && ...); } template <LessThanComparable... Args> constexpr bool are_sorted(Args&&... args) { if constexpr (sizeof...(Args) <= 1u) return true; else /// @note else needed to discard template instantiation of index sequence with sizeof...(T) - 1 with [T = 0] return are_sorted_impl(std::forward_as_tuple(std::forward<Args>(args)...), std::make_index_sequence<sizeof...(Args) - 1>{}); } int main() { std::vector<var_t> vec = {10, 15l, 1.5, "hello"}; for (auto& v : vec) { // void visitor, only called for side-effects std::visit([](auto&& arg) { std::cout << arg; }, v); // value-returning visitor; a common idiom is to return another variant v = std::visit([](auto&& arg) -> var_t { return arg + arg; }, v); std::cout << " after doubling is "; // type-matching visitor: can also be a class with 4 overloaded operator()s std::visit([](auto&& arg) { using T = std::decay_t<decltype(arg)>; if constexpr (std::is_same_v<T, int>) std::fmt::print("int with value {}\n", arg); else if constexpr (std::is_same_v<T, long>) std::fmt::print("long with value {}\n", arg); else if constexpr (std::is_same_v<T, double>) std::fmt::print("double with value {}\n", arg); else if constexpr (std::is_same_v<T, std::string>) std::fmt::print("std::string with value '{}'\n", arg); else static_assert(always_false<T>::value, "non-exhaustive visitor!"); }, v); } for (const auto& v : vec) { std::visit(overloaded { [](auto arg) { std::cout << arg << ' '; }, [](double arg) { std::cout << std::fixed << arg << ' '; }, [](const std::string& arg) { std::cout << std::quoted(arg) << ' '; } }, v); } } |
Clangd-based highlight
Uses clangd to colorize the code. No color file required, but the code must be compilable.
Clangd-based highlight is run when no colorizarion file is given. There is one additional option to enable specific subhighlights for printf family of functions.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
#include <iostream> #include <utility> #define EMPTY #define PRINT(x) \ std::cout << #x " = " << (x) << "\n" #ifndef EMPTY #define BUG #error Misconfigured build! #endif // some comment template <typename T> struct test { /** * @brief reset an object of type T * @param value the object * @return void */ void reset(T& value) const noexcept(noexcept(T{})) { // TODO make a version with T() value = EMPTY T{}; } template <typename U = T> decltype(auto) func(U&& object) const noexcept(noexcept(std::declval<U&&>().func())) { return std::forward<U>(object).func(); } }; [[nodiscard]] long long factorial(long long n) { if (n < 2) return 1; else return n * factorial(n - 1); } #define X(g, ...) auto global = /* not so multiline comment */ 123.456l; # /// lone hash shouldn't be a problem namespace anything { enum class something { one, two, three }; } auto main() -> int { test<decltype(global)>{}.reset(global); auto str_lit = R"test(raw\nstring\nliteral)test"; PRINT(str_lit); const auto& fmt = L"pointer = %p, length = %zu, string = %s"; std::cout << "sizeof(fmt) = " << sizeof(fmt) << "\n"; } |
Custom ANSI highlight
Support through rest_highlighter plugin. Path is mandatory.
notes/working.md at the root of the repository describes how to generate text files with ANSI highlight from colorful terminal output.
In file included from /usr/include/c++/8/algorithm:62, from main.cpp:1: /usr/include/c++/8/bits/stl_algo.h: In instantiation of ‘void std::__sort(_RandomAccessIterator, _RandomAccessIterator, _Compare) [with _RandomAccessIterator = std::_List_iterator<int>; _Compare = __gnu_cxx::__ops::_Iter_less_iter]’: /usr/include/c++/8/bits/stl_algo.h:4834:18: required from ‘void std::sort(_RAIter, _RAIter) [with _RAIter = std::_List_iterator<int>]’ main.cpp:7:30: required from here /usr/include/c++/8/bits/stl_algo.h:1969:22: error: no match for ‘operator-’ (operand types are ‘std::_List_iterator<int>’ and ‘std::_List_iterator<int>’) std::__lg(__last - __first) * 2, ~~~~~~~^~~~~~~~~ In file included from /usr/include/c++/8/bits/stl_algobase.h:67, from /usr/include/c++/8/algorithm:61, from main.cpp:1: /usr/include/c++/8/bits/stl_iterator.h:392:5: note: candidate: ‘template<class _IteratorL, class _IteratorR> constexpr decltype ((__y.base() - __x.base())) std::operator-(const std::reverse_iterator<_Iterator>&, const std::reverse_iterator<_IteratorR>&)’ operator-(const reverse_iterator<_IteratorL>& __x, ^~~~~~~~ /usr/include/c++/8/bits/stl_iterator.h:392:5: note: template argument deduction/substitution failed: In file included from /usr/include/c++/8/algorithm:62, from main.cpp:1: /usr/include/c++/8/bits/stl_algo.h:1969:22: note: ‘std::_List_iterator<int>’ is not derived from ‘const std::reverse_iterator<_Iterator>’ std::__lg(__last - __first) * 2, ~~~~~~~^~~~~~~~~ In file included from /usr/include/c++/8/bits/stl_algobase.h:67, from /usr/include/c++/8/algorithm:61, from main.cpp:1: /usr/include/c++/8/bits/stl_iterator.h:1188:5: note: candidate: ‘template<class _IteratorL, class _IteratorR> constexpr decltype ((__x.base() - __y.base())) std::operator-(const std::move_iterator<_IteratorL>&, const std::move_iterator<_IteratorR>&)’ operator-(const move_iterator<_IteratorL>& __x, ^~~~~~~~ /usr/include/c++/8/bits/stl_iterator.h:1188:5: note: template argument deduction/substitution failed: In file included from /usr/include/c++/8/algorithm:62, from main.cpp:1: /usr/include/c++/8/bits/stl_algo.h:1969:22: note: ‘std::_List_iterator<int>’ is not derived from ‘const std::move_iterator<_IteratorL>’ std::__lg(__last - __first) * 2, ~~~~~~~^~~~~~~~~
main.cpp: In function ‘int func(int&)’: main.cpp:7:1: warning: no return statement in function returning non-void [-Wreturn-type] } ^ main.cpp:3:15: warning: unused parameter ‘x’ [-Wunused-parameter] int func(int& x) ~~~~~^ main.cpp: In function ‘int main()’: main.cpp:12:25: error: ‘x’ was not declared in this scope std::cout << "x = " << x << "\n"; ^ main.cpp:13:7: error: cannot bind non-const lvalue reference of type ‘int&’ to an rvalue of type ‘int’ func(123); ^~~ main.cpp:3:5: note: initializing argument 1 of ‘int func(int&)’ int func(int& x) ^~~~
Comments
Any text which begins with an explicit markup start but doesn't use the syntax of any other construct, is a comment.
An "empty comment" does not consume following blocks. (An empty comment is ".." with blank lines before and after.)
Comments are started with explicit markup start (
..). It's quite complex how/when comments end, so IMO for multiline comments the best approach is to simply start each line with...Additionally, Visual Studio Code has been observed to parse and highlight comments incorrectly.